
1. 복합 인덱스 도입 배경 및 기존 쿼리 분석
버디야 서비스에서 피드를 조회할 때 다음과 같은 기준으로 조회한다.
@Query("""
SELECT f
FROM Feed f
WHERE f.university = :university
AND f.category = :category
ORDER BY f.pinned DESC, f.createdDate DESC
""")
Page<Feed> findFeedsByUnivAndCategory(
@Param("university") University university, @Param("category") Category category, Pageable pageable);학교와 카테고리(자유, 정보, 인기)로 게시글이 나눠져있고, 고정된(pinned) 게시글을 먼저, 그리고 최신순으로 가져오는 쿼리이다.
데이터 규모는 테스트 기준으로 대학 10개 × 카테고리 4개 × 조합당 10만 건 = 총 400만 건으로 설정하였다.
| Univ ID | Univ Name | Category | Count |
|---|---|---|---|
| 1 | sejong | free | 100000 |
| 1 | sejong | popular | 100000 |
| 1 | sejong | recruitment | 100000 |
| 1 | sejong | info | 100000 |
| 2 | konkuk | free | 100000 |
| 2 | konkuk | popular | 100000 |
| 2 | konkuk | recruitment | 100000 |
| 2 | konkuk | info | 100000 |
| 3 | seoulnational | free | 100000 |
| 3 | seoulnational | popular | 100000 |
| 3 | seoulnational | recruitment | 100000 |
| 3 | seoulnational | info | 100000 |
| 4 | yonsei | free | 100000 |
| 4 | yonsei | popular | 100000 |
| 4 | yonsei | recruitment | 100000 |
| 4 | yonsei | info | 100000 |
| 5 | korea | free | 100000 |
| 5 | korea | popular | 100000 |
| 5 | korea | recruitment | 100000 |
| 5 | korea | info | 100000 |
| 6 | sogang | free | 100000 |
| 6 | sogang | popular | 100000 |
| 6 | sogang | recruitment | 100000 |
| 6 | sogang | info | 100000 |
| 7 | hanyang | free | 100000 |
| 7 | hanyang | popular | 100000 |
| 7 | hanyang | recruitment | 100000 |
| 7 | hanyang | info | 100000 |
| 8 | chungang | free | 100000 |
| 8 | chungang | popular | 100000 |
| 8 | chungang | recruitment | 100000 |
| 8 | chungang | info | 100000 |
| 9 | kookmin | free | 100000 |
| 9 | kookmin | popular | 100000 |
| 9 | kookmin | recruitment | 100000 |
| 9 | kookmin | info | 100000 |
| 10 | sungkyunkwan | free | 100000 |
| 10 | sungkyunkwan | popular | 100000 |
| 10 | sungkyunkwan | recruitment | 100000 |
| 10 | sungkyunkwan | info | 100000 |
2. 테스트 환경과 비교 대상
실제 우리 서비스에서 피드 조회하는 쿼리와 똑같은 쿼리로 조회하기 위해 로그를 찍어보았다.
SELECT
f.id, f.category_id, f.comment_count, f.content,
f.created_date, f.is_profile_visible, f.like_count,
f.pinned, f.student_id, f.title, f.university_id,
f.updated_date, f.view_count
FROM feed f
WHERE f.university_id = 10
AND f.category_id = 2
ORDER BY f.pinned DESC, f.created_date DESC
LIMIT 1000;실험 테이블: feed (4000000 rows)
주요 컬럼: university_id, category_id, pinned(BOOL), created_date(DATETIME)
비교한 인덱스 구성 3종
1. 단일 인덱스 2개
CREATE INDEX university_id ON feed (university_id);
CREATE INDEX category_id ON feed (category_id);university_id와 category_id가 외래키인데 mysql에서 외래키는 자동으로 인덱스를 생성하기 때문에 피드 조회시 기본적으로 인덱스가 적용되는 상황이었다.
2. 복합 인덱스(조건만)
CREATE INDEX idx_feed_uni_cat
ON feed (university_id, category_id);첫번째 복합 인덱스는 where절에 있는 조건만 비교하였고 university_id가 전체 40개의 대학 목록이고, category_id는 4개밖에 없어서 선택도가 높은 university_id를 첫번째 인덱스 컬럼으로 설계하였다.
인덱스 컬럼 순서(선두 컬럼) 선택의 근거 — 선택도(Selectivity)
인덱스의 선두 컬럼은 조건을 가장 많이 걸러낼 수 있는(=선택도가 높은) 컬럼이 유리하다.
데이터 분포(총 4,000,000건)에서 평균적으로: category_id는 값이 4개 → 값 하나당 평균 약 1,000,000행 university_id는 값이 10개(테스트 기준) → 값 하나당 평균 약 400,000행
university_id + category_id 조합은 40개 → 조합 하나당 평균 약 100,000행
즉, category_id보다 university_id가 상대적으로 더 잘 데이터를 쪼개주므로, (university_id, category_id) 순서로 복합 인덱스를 설계했다.
3. 복합 인덱스(조건+정렬)
CREATE INDEX idx_feed_uni_cat_order
ON feed (university_id, category_id, pinned DESC, created_date DESC);두번째 복합 인덱스는 정렬 조건까지 포함하여 인덱스를 생성하기로 하였다.
3. 실행 계획 분석: 단일 vs 2컬럼 복합 인덱스 vs 4컬럼 복합 인덱스
실제 우리 서비스에서 피드 조회하는 쿼리와 똑같은 쿼리로 조회하기 위해 로그를 찍어보았다. 해당 쿼리를 API/네트워크 오버헤드가 발생할 수 있어 MySQL에서 쿼리를 직접 실행하였고 먼저 EXPLAIN ANALYZE의 actual time을 기준으로 비교하고 EXPLAIN으로 실행 계획을 분석하였다.
3-1. 단일 인덱스 2개 (university_id, category_id)

실행계획: index_merge → Using intersect(university_id,category_id); Using where; Using filesort
실행시간: ~296ms
university_id 인덱스와 category_id 인덱스를 각각 range scan한 뒤, RowID 교집합(intersect)을 수행한다.
이후 정렬(pinned DESC, created_date DESC)은 인덱스로 충족되지 않아 filesort(임시 정렬)이 필요하다.
- filesort란? MySQL이 인덱스를 쓰지 못하고 별도의 정렬 알고리즘을 수행하는 것 메모리(sort_buffer_size) 안에서 끝나면 빠르지만 데이터가 커서 메모리에 들어가지 않으면 디스크(임시 파일)에 쓰고 병함 -> 속도 느림
3-2. 복합 인덱스 2개 (university_id, category_id)

실행계획: ref → Index lookup on idx_feed_uni_cat + Using filesort
실행시간: ~121ms (약 2배 개선)
(university_id, category_id) 한 번의 인덱스 탐색으로 조건을 만족하는 연속 구간을 바로 스캔한다.
단일 인덱스와 비교해서 index_merge + 교집합이 사라져 조회 시간이 단축됐다.
다만 정렬 컬럼이 인덱스에 없으므로 filesort가 여전히 필요하다.
3-3. 복합 인덱스 4개 (university_id, category_id, pinned DESC, created_date DESC)

실행계획: ref → Index lookup on idx_feed_uni_cat_order (Extra: NULL)
실행시간: ~13ms
where + order by를 인덱스만으로 충족한다
결과 집합은 이미 인덱스 순서로 정렬되어 들어오므로 filesort가 완전히 제거된다.
정리
단일(index_merge)
- university_id=10 후보 RowID 집합 스캔
- category_id=2 후보 RowID 집합 스캔
- 두 집합 교집합 계산
- 정렬을 위해 filesort 수행
복합(university, category)
- (university, category) 하나의 B+Tree에서 연속 구간 range scan
- 후보 집합 축소가 매우 빠름
- 정렬 컬럼 포함하지 않아 filesort만 추가 수행
복합(university, category, pinned, created)
- (university, cat) 구간 스캔 + 인덱스 순서가 정렬 순서와 동일
- filesort 불필요
즉, 교집합 + 랜덤 접근이 많을수록 느리고, 한 인덱스에서 연속 스캔할수록 빠르다.
(근데 4컬럼 복합 인덱스도 커버링 인덱스는 아니기 때문에 인덱스 컬럼이 아닌 나머지 컬럼들을 가져오기 위해 인덱스로 얻은 Primary Key로 클러스터링 인덱스를 다시 타고감! -> 커버링 인덱스로 최적화 하고 싶지만 해당 쿼리에 조회 컬럼이 너무 많네요..)
4. 인덱스를 사용하면 무조건 좋은가?(트레이드 오프)
4-1. INSERT, UPDATE, DELETE 성능 저하
인덱스는 조회 성능이 향상된다는 장점이 있지만 INSERT, UPDATE, DELETE 시 인덱스도 같이 갱신해줘야 하므로 비용이 발생한다. 또한 인덱스도 디스크에 저장해야 하므로 인덱스 컬럼이 많아질수록 저장해야하는 데이터가 늘어난다. 따라서 무분별하게 사용하는 것이 아닌 조회가 많이 발생하고 인덱스 컬럼 변경이 잦지 않은 곳에 선택적으로 사용해야한다.
UPDATE
해당 쿼리의 경우 university, category, pinned, created으로 정렬을 수행하는데 university와 category를 지정하면 변경할 수 없고, pinned(고정 게시글)도 관리자가 변경하지 않는한 수정될 일이 없고, created_date(생성일)도 변경될 일이 없다.
DELETE
서비스 운영 시 게시글을 업로드하고 삭제하는 상황은 거의 발생하지 않았고 게시글을 업로드하는 상황이 많아 INSERT 성능을 중심으로 측정하였다.
INSERT 시간 측정
기존 400만건 데이터에 3가지 인덱스 상황을 적용했을 때 INSERT 시 얼마나 걸리는지 10번의 실행 후 평균 시간을 PROFILING으로 측정하였다.
SET profiling = 1;
SHOW PROFILES;단일 인덱스 : 1.19ms
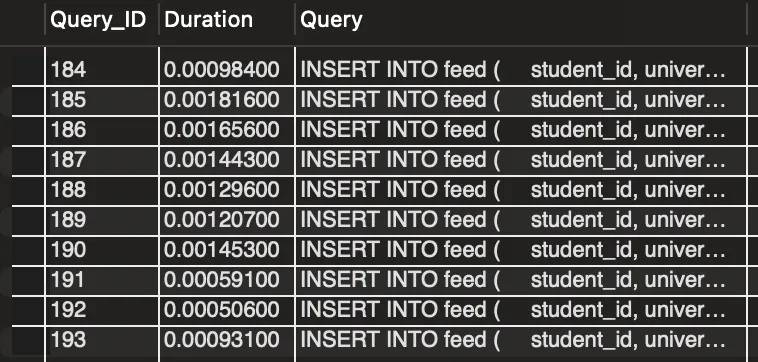
복합 인덱스(2컬럼) : 1.42ms(+19%)
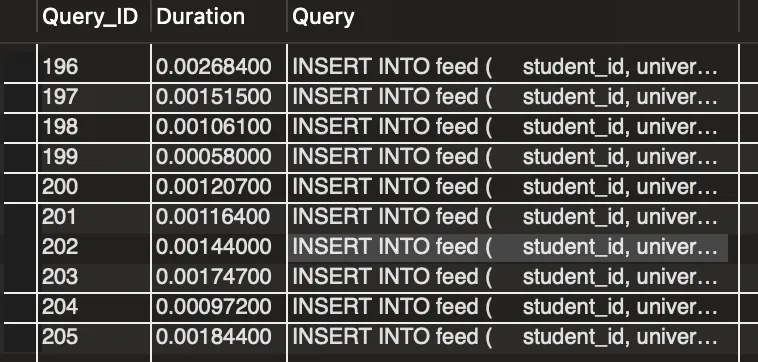
복합 인덱스(4컬럼) : 1.54ms(+29%)
현재 데이터가 400만개일 때의 측정 결과인 것이고 인덱스가 B+Tree 구조이기 때문에 데이터가 많아질수록 트리 깊이가 깊어져 시간이 더 오래 걸릴 것이다.
4-2. 인덱스 디스크 사용량
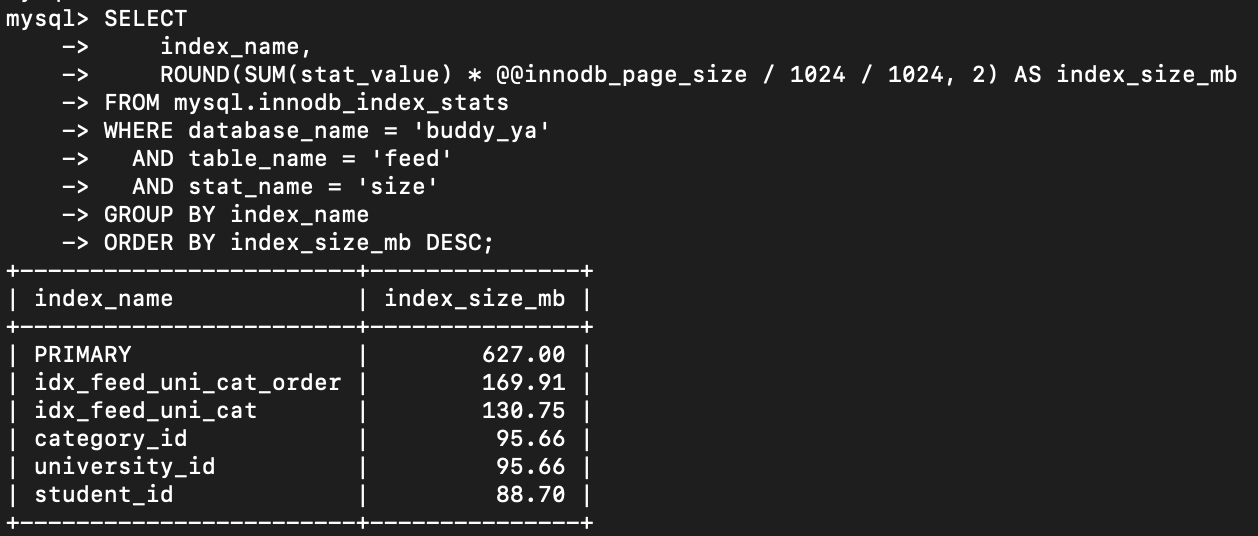
분석해보니 역시 PRIMARY KEY가 클러스터링 인덱스이므로 모든 레코드의 실제 데이터가 포함되어 있어 가장 많은 용량을 차지했다.
- 단일 인덱스 1개가 차지하는 용량은 95MB
- 복합 인덱스(2컬럼: idx_feed_uni_cat)는 130MB
- 복합 인덱스(4컬럼: idx_feed_uni_cat_order)는 169.91MB
5. 트레이드 오프를 고려한 인덱스 적용
인덱스 설계하기 전 목표는 대학교+카테고리로 필터한 뒤 고정 게시글 우선·최신순 정렬을 가장 빠르게 제공하는 것. 이를 위해 세 가지 대안을 실제로 측정해보았다.
5-1. 장점
조회 시간 개선
- 단일 인덱스: 296ms (기준)
- 복합 인덱스(2컬럼): 121ms (−175ms, −59.05%)
- 복합 인덱스(4컬럼): 13ms (−283ms, −95.61%)
5-2. 단점
쓰기 성능 저하(10회 평균)
- 단일 인덱스: 1.19ms
- 복합 인덱스(2컬럼): 1.42ms(+0.23ms, +19.33%)
- 복합 인덱스(4컬럼): 1.54ms (+0.35ms, +29.41%)
디스크 용량 증가
- 단일 인덱스: 95.66MB
- 복합 인덱스(2컬럼): 130.00MB (+34.34MB, +35.9%)
- 복합 인덱스(4컬럼): 169.91MB (+74.25MB, +77.6%)
하지만 해당 API는 읽기 비중이 절대적으로 높고, 운영상 pinned 변경 빈도도 낮아 쓰기 비용 증가는 제한적이었다. 또한 디스크 저장 공간 비용이 발생하더라도 가장 많이 사용하는 조회 API이고, 성능 조회의 이점이 너무 명확하여 사용해도 되겠다라고 판단하였다. 따라서 핵심 조회 API에는 (university_id, category_id, pinned DESC, created_date DESC) 4컬럼 복합 인덱스를 적용하였다.
6. 성과와 느낀점
인덱스를 적용하기 전 MySQL에서 B+Tree 구조와 인덱스가 어떻게 관리되는지를 공부하고 적용 후 측정해보니 예상했던 결과와 비슷하게 나오는 점이 흥미로웠다. 이전에는 인덱스를 적용하여 쿼리 성능 개선해야지라는 생각으로 인덱스의 단점을 배제하고 적용했지만 잘못된 인덱스 적용이라는 것을 깨달았다. 쓰기와 수정, 디스크 비용을 희생하기 때문에 이 단점들을 감수하고라도 조회 성능 개선이 중요한 지점에만 설정해야 한다는 것을 알았다. (커버링 인덱스로 적용해보고 싶었는데 너무 많은 필드를 가져오는지라 나중에 따로 적용해봐야겠다..)