
인식한 문제
서비스를 운영하던 중 관리자가 신고된 채팅방의 채팅방 메시지를 조회할 때 채팅 메시지가 많아질 수록 데이터 조회하는 속도가 느려지는 성능 저하 문제를 발견하였다. 조회에서 성능이 나오지 않는 경우 쿼리를 보낼 때 예상하던 것과 다르게 나타나는 경우가 많아 log로 쿼리를 찍어 테스트 해보기로 하였다. 먼저 간단하게 쿼리를 분석하기 전 Entity 구조와 조회 로직에 대해 살펴보고자 한다.
기존 설계 방식 분석
도메인 구조 파악
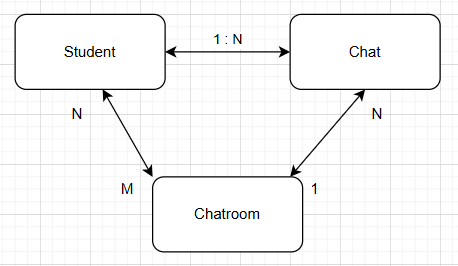
Entity의 필드가 실제로 더 많지만 관련된 내용을 설명하기 위해 관련된 부분만 가져왔다.
Student
@Entity
public class Student extends BaseTime {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
@Column(length = 64, nullable = false)
private String name;
@Column(name = "email", unique = true)
private String email;
@OneToMany(mappedBy = "student", cascade = CascadeType.REMOVE, orphanRemoval = true)
private List<StudentMajor> majors;
@OneToOne(mappedBy = "student", cascade = CascadeType.REMOVE, orphanRemoval = true)
private Avatar avatar;
@OneToOne(mappedBy = "student", cascade = CascadeType.REMOVE, orphanRemoval = true)
private ProfileImage profileImage;
@OneToOne(mappedBy = "student", cascade = CascadeType.REMOVE, orphanRemoval = true)
private AuthToken authToken;
@OneToOne(mappedBy = "student", cascade = CascadeType.REMOVE, orphanRemoval = true)
private StudentIdCard studentIdCard;
@OneToOne(mappedBy = "student", cascade = CascadeType.REMOVE, orphanRemoval = true)
private ExpoToken expoToken;
}Student 엔티티는 학생에 대한 정보를 가지고 있다. Avatar, ProfileImage, AuthToken, StudentIdCard, ExpoToken 엔티티와 @OneToOne의 연관관계를 맺고 있다.
Chatroom
@Entity
public class Chatroom extends CreatedTime {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "last_message")
private String lastMessage;
@Column(name = "last_message_time", nullable = false)
private LocalDateTime lastMessageTime;
@OneToMany(mappedBy = "chatroom", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Chat> chats;
}Chatroom은 채팅방이며 하나의 채팅방에 여러 메시지(Chat)를 저장할 수 있다.
Chat
@Entity
public class Chat extends CreatedTime {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "chatroom_id", nullable = false)
private Chatroom chatroom;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "student_id", nullable = false)
private Student student;
@Column(name = "message", nullable = false, columnDefinition = "TEXT")
private String message;
@Enumerated(EnumType.STRING)
@Column(nullable = false)
private MessageType type;
}Chat은 채팅방 메시지이며 Chatroom, Student와 연관 관계를 맺고있다.
채팅 메시지 조회 로직
채팅방 메시지 조회 로직은 간단하다.
public List<AdminChatMessageResponse> getAllChatMessages(Long chatroomId) {
// 1. 채팅방 조회
Chatroom chatroom = chatroomRepository.findById(chatroomId)
.orElseThrow(() -> new ChatException(ChatExceptionType.CHATROOM_NOT_FOUND));
// 2. 채팅방으로 채팅 메시지 조회
List<Chat> chats = chatRepository.findByChatroom(chatroom);
// 3. 채팅 메시지로 Dto를 만들어 반환
return chats.stream()
.map(AdminChatMessageResponse::from)
.toList();
}public interface ChatRepository extends JpaRepository<Chat, Long> {
List<Chat> findByChatroom(Chatroom chatroom);
}public record AdminChatMessageResponse(
Long id,
String senderName,
Long senderId,
MessageType type,
String message,
LocalDateTime createdDate
) {
public static AdminChatMessageResponse from(Chat chat) {
return new AdminChatMessageResponse(
chat.getId(),
chat.getStudent().getName(),
chat.getStudent().getId(),
chat.getType(),
chat.getMessage(),
chat.getCreatedDate()
);
}
}chatroomId로 채팅방을 조회한다.- 조회한 채팅방으로
채팅 메시지 조회한다. - 조회한 채팅 메시지로
dto를 만들어 반환한다.
쿼리를 분석하기 위해 한 채팅방에 10명의 대화자가 각 1개씩 총 10개의 메시지를 보낸 상황을 가정해보겠다. 그리고 관리자가 메시지들을 조회하고 쿼리를 로그로 확인하여 보았다.
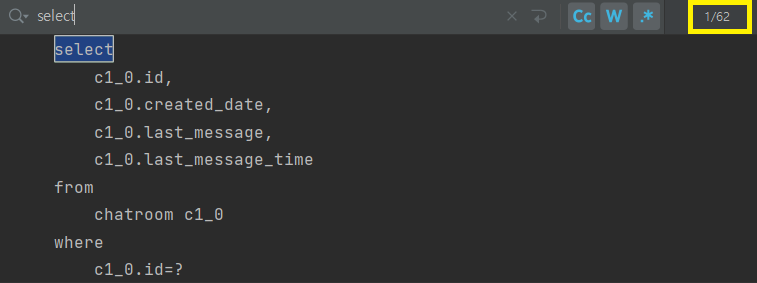
그 결과 총 62개의 쿼리가 발생하였다. 먼저 62개 중 2개의 쿼리를 분석해보자.
1. 채팅방 조회 쿼리
select
c1_0.id,
c1_0.created_date,
c1_0.last_message,
c1_0.last_message_time
from
chatroom c1_0
where
c1_0.id=?먼저 하나는 채팅방을 조회하는 쿼리로 chatroomRepository.findById(chatroomId) 에서 발생한 것으로 확인했다.
2. 채팅 메시지 조회 쿼리
select
c1_0.id,
c1_0.chatroom_id,
c1_0.created_date,
c1_0.message,
c1_0.student_id,
c1_0.type
from
chat c1_0
where
c1_0.chatroom_id=?다른 한 가지 쿼리는 채팅 메시지 조회할 때 chatRepository.findByChatroom(chatroom) 다음과 같은 repository를 조회할 때 발생하였다.
이 두가지 쿼리는 내가 예상한 흐름과 동일하였다.
하지만 채팅 메시지 1개 조회당 6개의 쿼리(10 x 6)가 추가로 발생하였다.
쿼리 발생 지점
- 채팅방 조회 - 1개
- 채팅 메시지 10개 조회 - 1개
- 채팅 메시지 1개당 6개
- Student - 1개
- Avatar - 1개
- ProfileImage - 1개
- AuthToken - 1개
- StudentIdCard - 1개
- ExpoToken - 1개
-> 1 + 1 + 6 x 10 = 62
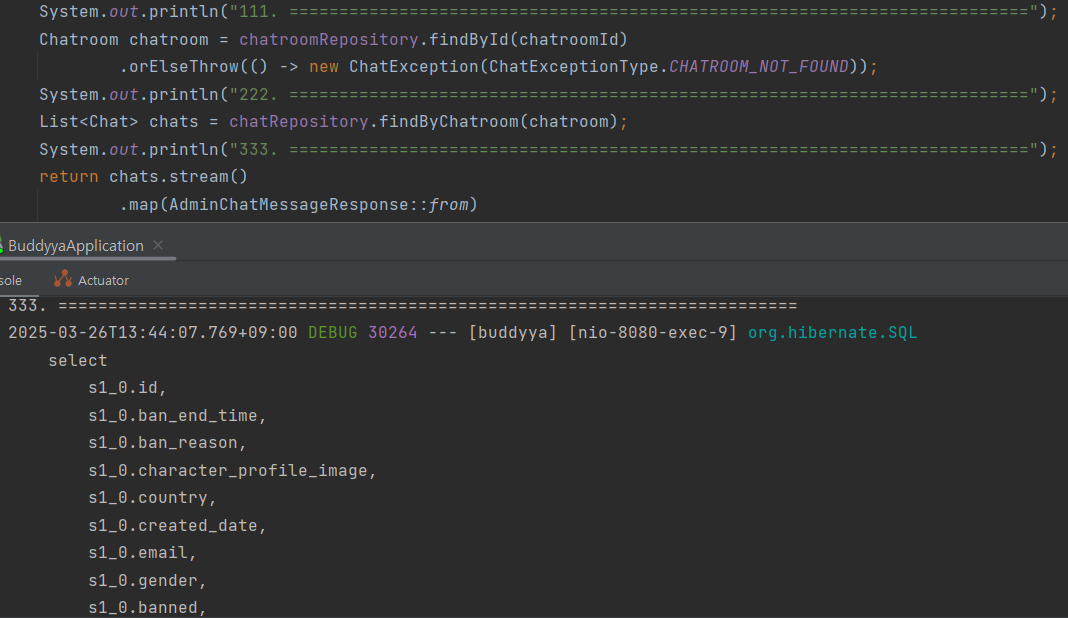
쿼리 발생 지점을 분석해보니 Chat으로 Dto를 만들 때 60개의 쿼리가 발생하는 것을 파악할 수 있었다.
public static AdminChatMessageResponse from(Chat chat) {
return new AdminChatMessageResponse(
chat.getId(),
chat.getStudent().getName(),
chat.getStudent().getId(),
chat.getType(),
chat.getMessage(),
chat.getCreatedDate()
);
}이 중에서도 chat.getStudent().getName() Chat으로 Student를 조회하고 학생 name을 가져올 때가 문제였다.
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "student_id", nullable = false)
private Student student;Chat에서 Student를 지연로딩(fetch = LAZY)을 하였기 때문에 List
하지만 chat.getStudent().getName()을 할 때 실제 student의 Name이 필요하므로 해당 시점에 결국 쿼리를 보내 Student를 조회하는 것이다.
Student를 조회할 때 Student와 @OneToOne 연관 관계가 맺어진 Avatar, ProfileImage, AuthToken, StudentIdCard, ExpoToken 엔티티도 같이 조회가 되어어 추가적으로 5번의 쿼리가 발생했다.
이를통해 문제 원인과 지점까지 파악하였고 해당 문제를 해결하기 위한 방법이 필요했다.
해결 과정
1. fetch join으로 N + 1 문제 해결하기
1-1. chatroom만 fetch join
이 문제를 해결하기 위해 구글링을 하였고 fetch join 쿼리 작성을 통해 별도의 쿼리를 발생시키지 않고 쿼리를 한꺼번에 가져오는 방식을 도입하고자 하였다.
@OneToOne(mappedBy = "student", cascade = CascadeType.REMOVE, orphanRemoval = true, fetch = LAZY)
private Avatar avatar;그 전에 Student를 조회할 때 Avatar, ProfileImage, AuthToken, StudentIdCard, ExpoToken가 같이 조회되는데 해당 로직에서는 사용하지 않도록 fetch = LAZY로 지연 로딩 설정을 먼저 해주었다.
//기존 채팅방 메시지 가져오기
List<Chat> findByChatroom(Chatroom chatroom);
//fetch join을 도입하여 채팅방 메시지 가져오기
@Query("SELECT c FROM Chat c JOIN FETCH c.student WHERE c.chatroom = :chatroom")
List<Chat> findChatsWithStudentOnly(@Param("chatroom") Chatroom chatroom);
그리고 채팅 메시지 Chat을 가져올 때 Student도 함께 조회하여 chat.getStudent().getName()시 추가적인 쿼리를 발생 시키지 않도록 fetch join 쿼리를 설정하였다.
이제 예상하는 쿼리는
- 채팅방 조회 - 쿼리 1개
- 채팅 메시지 10개 조회(Student도 같이 조회됨, Fetch = LAZY로 설정한 @OneToOne 연관 관계는 가져오지 않음) - 쿼리 1개
이렇게 2개가 나올 것으로 예상하였다.
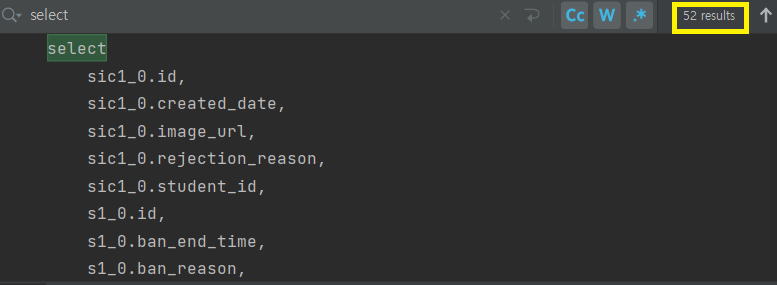
그 결과 총 52개의 쿼리가 발생하였다.
예상과 달리 많은 쿼리의 수가 나와 분석해보니 Student 필드에 @OneToOne 연관 관계 (Avatar, ProfileImage, AuthToken, StudentIdCard, ExpoToken)가 조회되는 쿼리가 여전히 발생하였다. 62 -> 52개로 줄어든 이유는 위에서 fetch join 설정을 하여 Chat을 가져올 때 Student를 같이 가져오기 때문에 10개의 쿼리가 단축된 것이다.
Question?분명 방금 Student 필드의 @OneToOne 연관 관계에 대해서 지연 로딩을 설정했는데 왜 여전히 Student 조회 시 쿼리를 보내 같이 조회가 될까?
@OneToOne 지연 로딩 적용되지 않는 문제
@OneToOne에 지연 로딩이 적용되지 않는 문제를 정리한 글이 있어 해당 글을 참고하였다. https://jeong-pro.tistory.com/249
해당 글에서 잘 정리하였기에 결론만 설명하자면
- 연관관계의 주인이 아닌 엔티티는 외래키 컬럼이 없어 연관된 엔티티의 존재 여부를 즉시 확인할 수 없다.
- 외래키 없이 LAZY 로딩을 시도하면 JPA 구현체가 프록시 객체를 생성할 수 없으며, 데이터 존재 여부를 확인하기 위해 추가 쿼리가 필요하다.
- 결과적으로 성능상의 이점을 잃게 되어
LAZY 설정이 무의미해지고, 자동으로 EAGER 로딩 방식으로 동작하게 된다.
1-2. fetch join으로 @OneToOne 연관 관계도 한꺼번에 조회하기
@OneToOne 지연 로딩 안되는 문제를 해결하는 방법이 여러가지가 있었지만 도메인 구조를 바꾸지 않고 해결하는 가장 쉬운 방법은 fetch join으로 해당 엔티티들을 같이 가져오는 것이다.
Chat조회 시 Student 뿐만이 아니라 Avatar, ProfileImage, AuthToken, StudentIdCard, ExpoToken 엔티티들도 같이 가져오도록 하였다.
@Query("""
SELECT DISTINCT c
FROM Chat c
JOIN FETCH c.student s
LEFT JOIN FETCH s.avatar
LEFT JOIN FETCH s.profileImage
LEFT JOIN FETCH s.authToken
LEFT JOIN FETCH s.studentIdCard
LEFT JOIN FETCH s.expoToken
WHERE c.chatroom = :chatroom
""")
List<Chat> findChatsWithStudentDetails(@Param("chatroom") Chatroom chatroom);기존에 채팅 메시지들을 조회할 때 Student만 fetch join으로 갖고 왔지만 다음과 같이 @OneToOne 엔티티들을 join하여 가져오는 쿼리를 작성하였다.
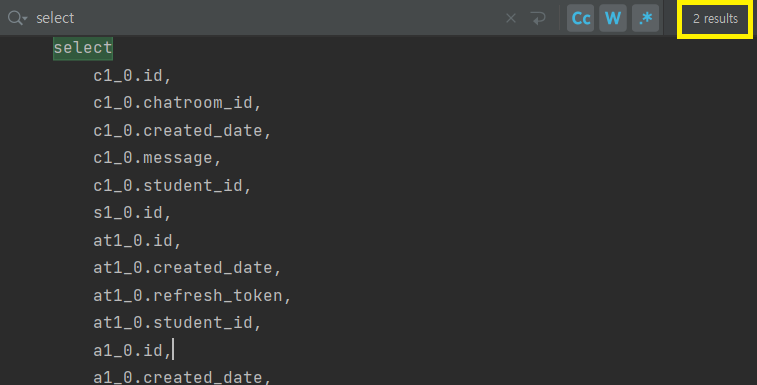
그 결과 총 2개의 쿼리가 발생한 것을 확인할 수 있다.
- 채팅방 조회 - 1개
- 채팅 메시지 조회 - 1개
2. BatchSize를 활용하여 N + 1 문제 해결하기
spring.jpa.properties.hibernate.default_batch_fetch_size=100N + 1을 해결하는 대표적인 방법 중에 하나가 Batch Size이다. Batch Size는 N + 1 쿼리 처럼 쿼리를 나눠서 실행하지 않고 IN 절을 통해서 쿼리를 실행하는 것이다.
위 설정을 하고 채팅 메시지를 조회하면 N + 1 문제가 발생하지 않고 IN 절을 통해 한번의 쿼리가 실행된다고 예상했다.
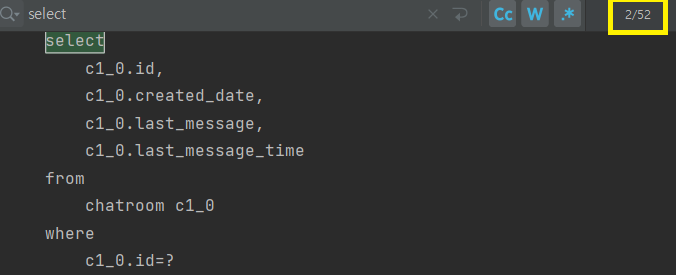
하지만 결과는.. 기존 Student만 fetch join 하여 가져온 결과와 동일하였다.
결과가 달리지지 않는 이유는 위에서 설명했듯 @OneToOne에서는 지연 로딩이 적용되지 않고, 해당 객체가 null 인지 아닌지를 알아야 하기에 조회해야 하는 문제 때문에 N + 1 문제는 Batch Size로는 해결할 수 없었다
3. DTO Projection을 활용하여 N + 1 문제 해결하기
위에서 Fetch Join을 활용하여 문제를 해결할 때 쿼리는 다음과 같다.
JOIN FETCH c.student s
LEFT JOIN FETCH s.avatar
LEFT JOIN FETCH s.profileImage
LEFT JOIN FETCH s.authToken
LEFT JOIN FETCH s.studentIdCard
LEFT JOIN FETCH s.expoToken다음과 같이 사용하지도 않는 엔티티들을 단지 @OneToOne에서 LAZY가 적용되지 않는다고 Fetch Join을 하여 가져왔었다.
그렇다면 필요하지 않은 필드를 가져오지 않는 방법은 없을까 해서 찾아본 방법이 DTO Projection을 사용하는 방식이었다.
DTO Projection이란?엔티티 전체를 조회하지 않고, 원하는 필드만 골라서 DTO(데이터 전송 객체)로 바로 매핑해 조회하는 방식
@Query("""
SELECT new com.team.buddyya.admin.dto.response.AdminChatMessageDto(
c.id,
s.id,
s.name,
c.type,
c.message,
c.createdDate
)
FROM Chat c
JOIN c.student s
WHERE c.chatroom = :chatroom
""")
List<AdminChatMessageDto> findChatDtosByChatroom(@Param("chatroom") Chatroom chatroom);다음과 같이 내가 필요한 필드만 select하여 dto로 변환하여 가져올 수 있다.
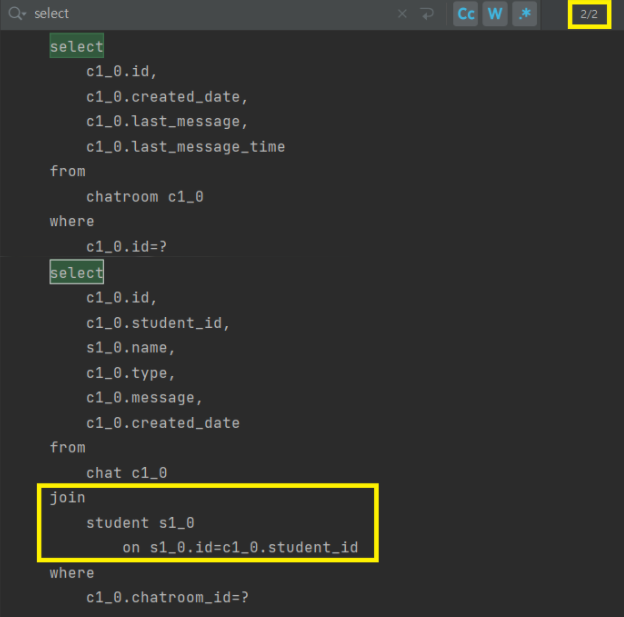
쿼리를 확인해보면 채팅방 조회, 채팅 조회 쿼리가 2개 발생하는데 이전에 모든 필드를 가져오는 것과 달리 student만 join해서 가져오는 것을 확인할 수 있다.
성능 비교
그렇다면 다음과 같이 쿼리 수는 줄였는데 성능상에서 이점이 얼마나 있을까?
데이터가 적은 경우 네트워크 지연으로 인해 차이가 미미할 수 있으니 데이터 5000개를 기준으로 테스트 해보았다.
1. 기본 쿼리

가장 먼저 fetch join을 적용하지 않은 프로젝트에서 사용했던 방식을 조회하였다. Student와 연관 관계 맺어진 모든 데이터를 일일이 가져오다 보니 1분 16.74초가 걸린 것을 확인할 수 있다.
2. Fetch Join
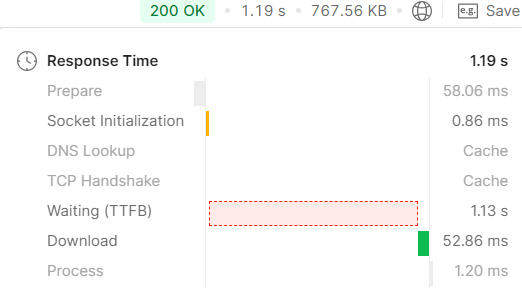
두 번째로 관련된 데이터들을 fetch join하는 방식으로 조회하였다. 첫 번째 방식보다 역시 join해서 관련된 필드를 가져오니 훨씬 빨라졌다. 1.19초가 걸린 것을 확인할 수 있다.
3. DTO Projection
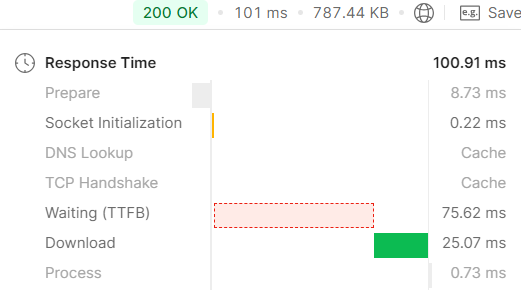
마지막은 사용하지 않는 엔티티들을 fetch join하지 않고 사용되는 필드만 조회하여 dto로 변환하여 가져오는 DTO Projection 방식이다. 101ms로 약 0.1초가 걸린 것을 확인할 수 있다.
결과
메시지들이 많아질 수록 조회 시간이 기하 급수적으로 증가하는 문제가 있었고 이를 불필요한 연관 엔티티 조회 x, 필요한 필드만 선택적으로 조회하여 성능 개선을 하였다.
기존에는 N + 1문제에서 지연로딩 + fetch join을 하면 해결된다라고 알고 있었지만 실제로 적용해보니 성능 개선은 되었지만 쓰지 않는 엔티티들을 join 한다는 것에 의문점을 가졌고 이를 DTO Projection으로 필요한 필드만 조회하는 방식을 도입하여 해결하였다.
결과적으로 채팅 데이터 10건 기준 쿼리 62 -> 2, 데이터 5000건 기준 조회 시간 1m16s -> 0.1s 로 성능 개선을 하였다.