
1. 도입 배경
버디야 서비스에서 피드 목록은 좋아요 수를 함께 보여준다. 초기엔 Feed–FeedLike를 완전 정규화로 설계하여 무결성을 확보했다. 하지만 피드 개수가 많아질수록 조회 시간이 점점 길어졌고 기존에 해결했던 N + 1문제 이외에 게시글 하나 조회 시 feed_like의 개수를 일일이 count(*)하는 방식으로 계산한 것이 지연의 원인이었다.
2. 문제와 해결
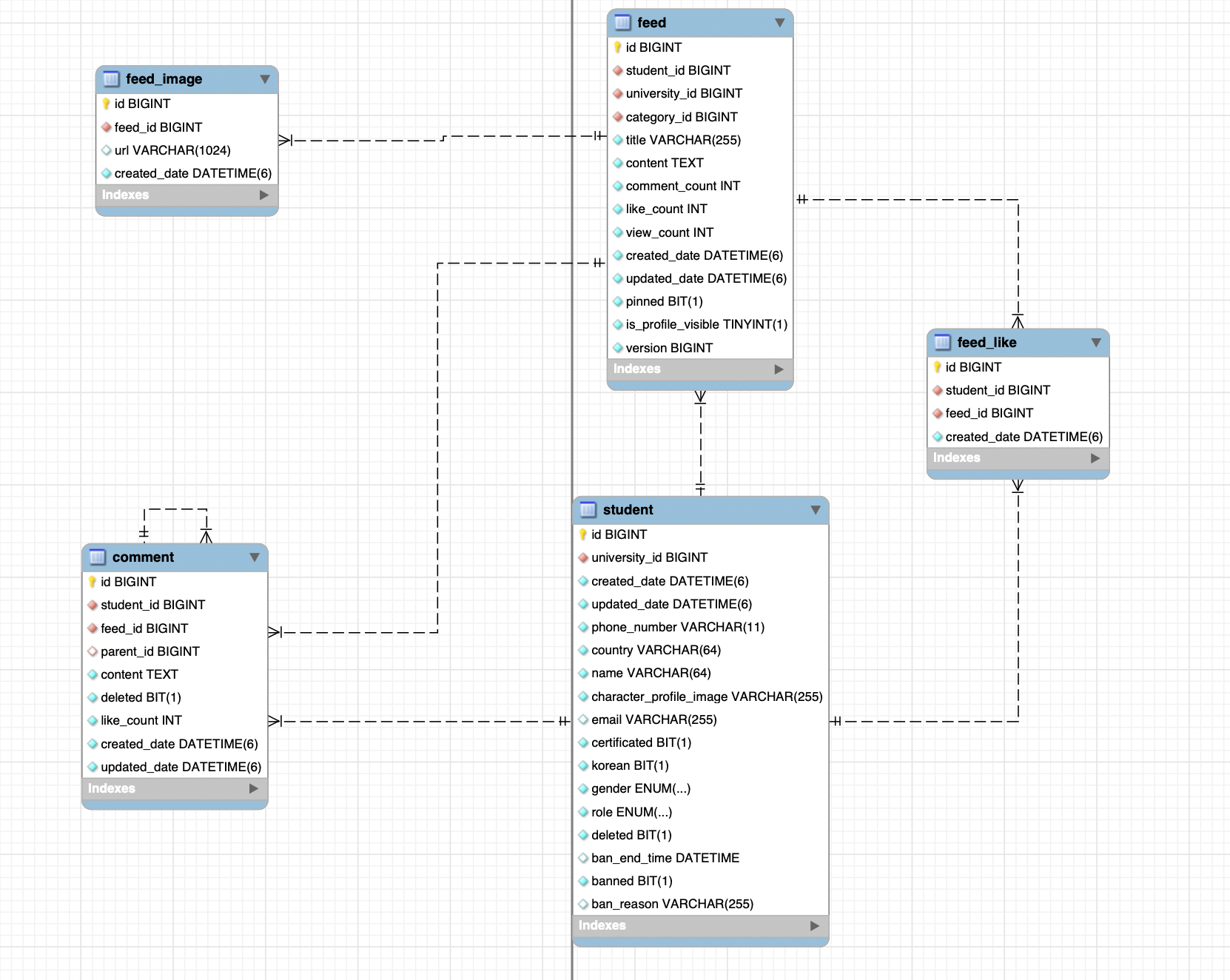
Feed - FeedLike 관계
- Feed(id, author_id, created_at, …)
- FeedLike(feed_id, user_id, created_at, …) — (feed_id, user_id) UNIQUE
문제 상황 FeedLike 테이블은 (feed_id, user_id) UNIQUE 제약이 있어 인덱스가 자동 생성된다. 이 덕분에 특정 사용자의 좋아요 여부는 빠르게 확인할 수 있었지만, 게시물 목록 조회에서는 N개의 게시물마다 COUNT 쿼리를 반복 실행해야 했습니다. 결국 인덱스만으로는 COUNT 누적 비용 자체를 줄일 수 없었고, **반정규화(Feed.like_count)**를 적용해 읽기 경로를 단순화하는 게 읽기가 빈번한 상황에서 유리하다고 판단하였다.
반정규화 도입 시 트레이드오프
- 쓰기 비용 증가: 이제 좋아요/취소 시 FeedLike(원천)와 Feed.like_count(파생)를 둘 다 갱신해야 함.
- 동시성/정합성 리스크: 경쟁 상황에서 카운터가 어긋날 수 있음.
반정규화 선택
- 피드 목록은 빈번한 읽기 작업이므로 응답 속도 줄이는 것이 중요하다고 생각 → COUNT(*) 자체를 없애는 게 효과적.
- 따라서 Feed.like_count 반정규화를 도입하고, 트랜잭션으로 원자성을 보장하여 정합성을 확보하기로 결정.
스키마 변경
ALTER TABLE feed ADD COLUMN like_count INT NOT NULL DEFAULT 0;- Feed 테이블에 like_count 필드 추가
UPDATE feed f
SET f.like_count = (
SELECT COUNT(*)
FROM feed_like fl
WHERE fl.feed_id = f.id
);- default를 0으로 하면 정합성이 깨지기 때문에 기존에 feed_like 개수를 like_count에 초기값으로 설정
원자적 갱신(트랜잭션)
@Transactional
public LikeResponse toggleLike(StudentInfo info, Long feedId) {
Feed feed = feedRepository.findByIdForUpdate(feedId)
.orElseThrow(() -> new NotFoundException("feed"));
boolean exists = feedLikeRepository.existsByFeedIdAndUserId(feedId, info.id());
if (!exists) {
feedLikeRepository.save(new FeedLike(feedId, info.id()));
feed.increaseLikeCount();
return LikeResponse.from(true, feed.getLikeCount());
} else {
feedLikeRepository.deleteByFeedIdAndUserId(feedId, info.id());
feed.decreaseLikeCount();
return LikeResponse.from(false, feed.getLikeCount());
}
}- 원자성: 실패 시 전체 롤백 → FeedLike와 like_count가 동기화 상태 유지
- 멱등성: FeedLike(feed_id, user_id) UNIQUE로 중복 좋아요 삽입 차단
3. 성과
반정규화(카운터 캐시) 도입 이후, 목록 조회 경로에서 COUNT(*)가 사라지면서 게시글 조회 시 feed_like를 일일이 계산하지 않고 조회로 개선하여 DB부하를 감소시켰다. 처음에 데이터 모델링을 설계할 때는 정규화를 잘 지키는 것이 이상을 줄이는 방법이라고 배웠는데 count와 같이 조회 시 매번 계산해야 되는 상황에서는 사용자에게 얼마나 빨리 응답할 수 있을까? 라는 관점에서 고민해봐야 하는 것 같다. 데이터의 무결성을 깨뜨릴 위험이 있으므로 일관성과 성능 사이에서 적절한 균형을 찾는 것 또한 중요하다고 느꼈다.