
1. 도입 배경
학교에서 홍보 부스를 진행하기 전 이벤트로 인한 사용자 급증에 대비하여 방안을 마련하기로 하였다. 기존 서버 환경에서는 트래픽 급증 시 CPU 사용률이 급격히 상승하여 서비스 장애가 발생할 위험성이 존재했다. 특히 홍보 이벤트와 같이 예측 가능한 트래픽 증가 상황에서도 실시간 모니터링 체계가 부재하여 장애 대응이 지연될 가능성이 있었다. 따라서 사전 예방적 모니터링 시스템을 구축하여 CPU 사용률이 임계값(70%)을 초과할 경우 즉시 담당자에게 알림을 전송하는 자동화된 모니터링 체계를 마련하기로 결정하였다.
2. 해결 과정
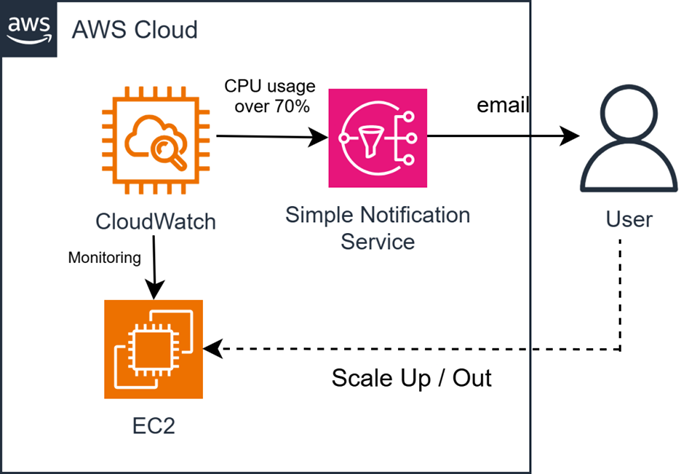
간단하게 아키텍처는 다음과 같다.CPU 사용량이 70%가 넘었을 때 CloudWatch에서 SNS로 사용자에게 이메일을 전송하고 사용자가 ScaleOut이나 ScaleUp을 통해 장애에 대응하는 것이다.
- CloudWatch와 SNS
- Prometheus + Grafana + AlertManager 모니터링 + 알림 체계 구축에서 두 방법을 고민하였지만 홍보 부스 운영하는 날이 당장 다음 날이라 별도의 서버 인프라 구축이 필요한 Prometheus보다 구축 부담이 적은 Cloud Watch + SNS를 사용하였다.
따라서 사용 이유는 다음과 같이 정리해볼 수 있겠다
기존 서비스가 EC2 인스턴스 기반으로 운영 중당장 모니터링과 알림 체계가 필요한 상황에서 추가 인프라 구축 불필요
설정하는 방법은 다음과 같다.
1. 경보 & 지표 생성
cloud watch → 경보 → 경보 생성
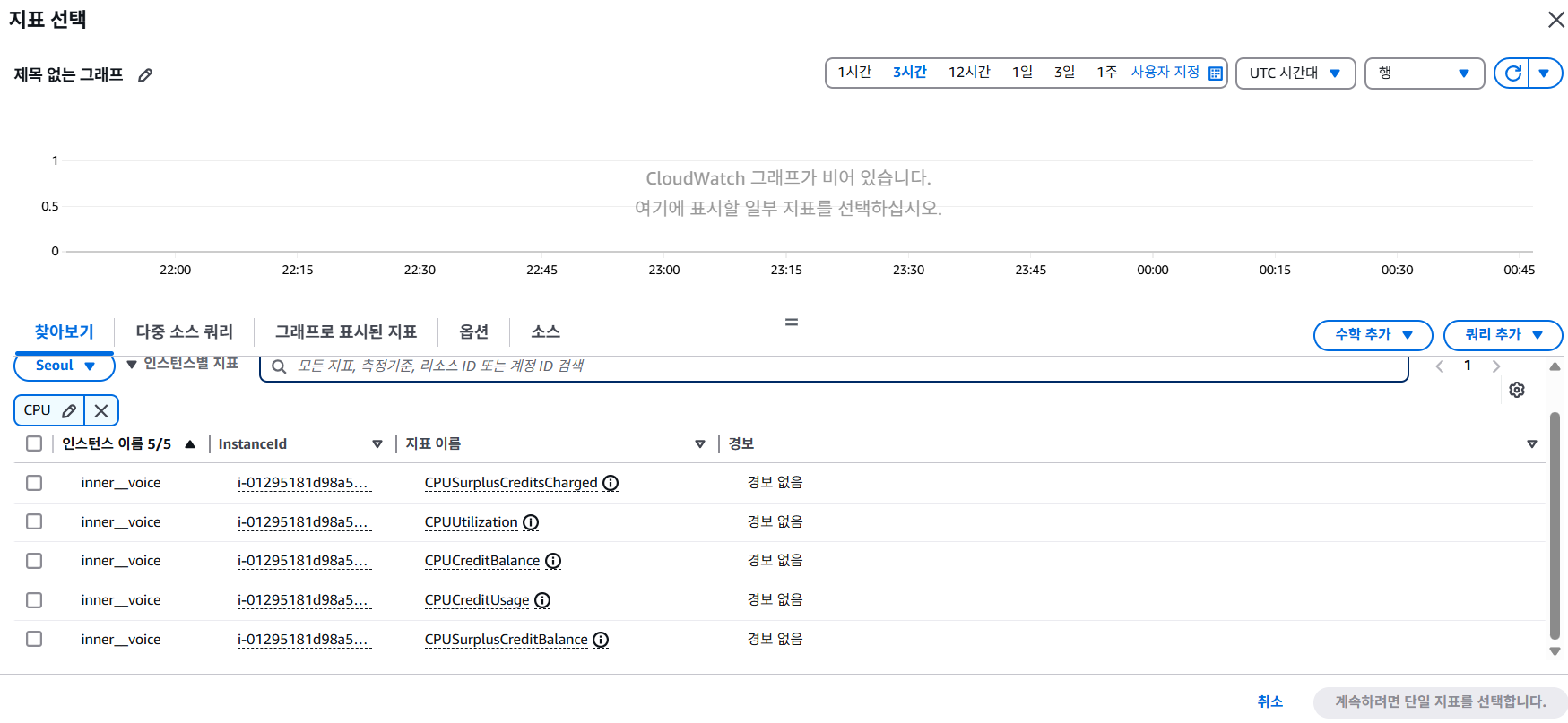
- 지표 선택 → ec2 → 인스턴스별 지표 → ec2 인스턴스 선택 → CPU Utilization
CPU 사용량에 대한 임계값을 설정하기 위해 CPU Utilization 지표를 선택했지만 CPU 사용률 이외에 디스크 읽기, 인바운드 트래픽 등 다양한 지표를 선택할 수 있다.
2. 데이터 표시 및 임계값 설정
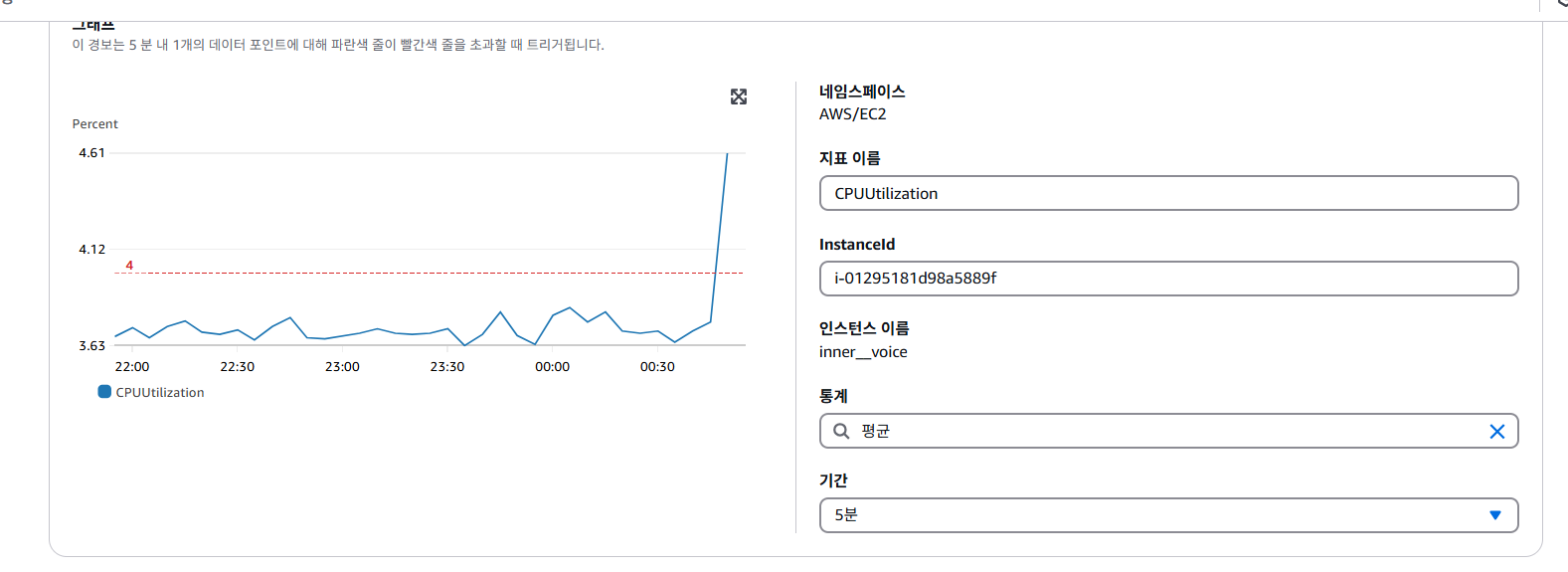
다음은 수집된 데이터를 어떤 주기로 어떻게 표시할 것인지 설정한다. Maximum은 민감하게 반응하고 Minimum은 설정하면 실제 지표보다 과소평과 될 위험이 있어 Average로 5분동안 수집된 모든 데이터의 평균을 표시하도록 설정하였다.
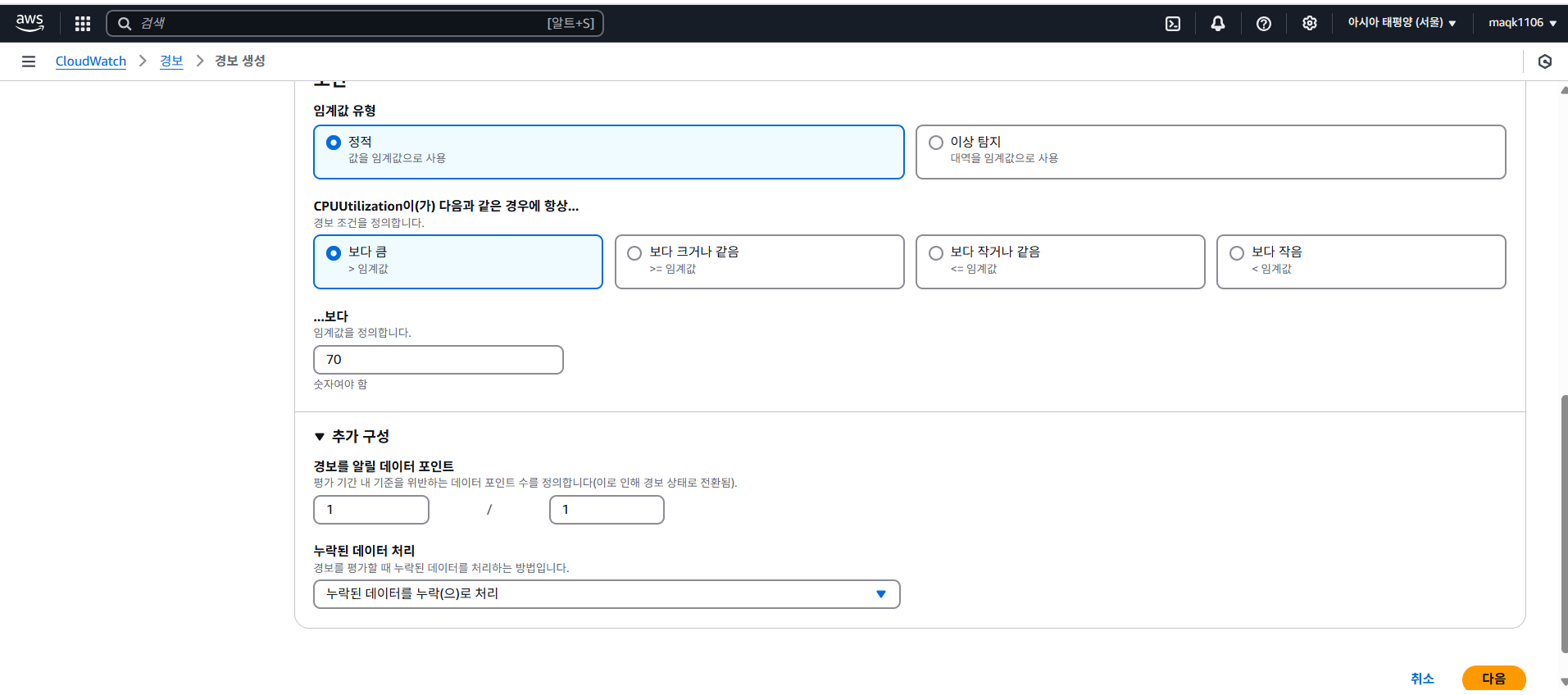
CPU 사용률이 70% 이상일 때 경보가 발생하게 되도록 수치를 설정해주었다.
3. 경보 발생 시 알림 받을 이메일 설정
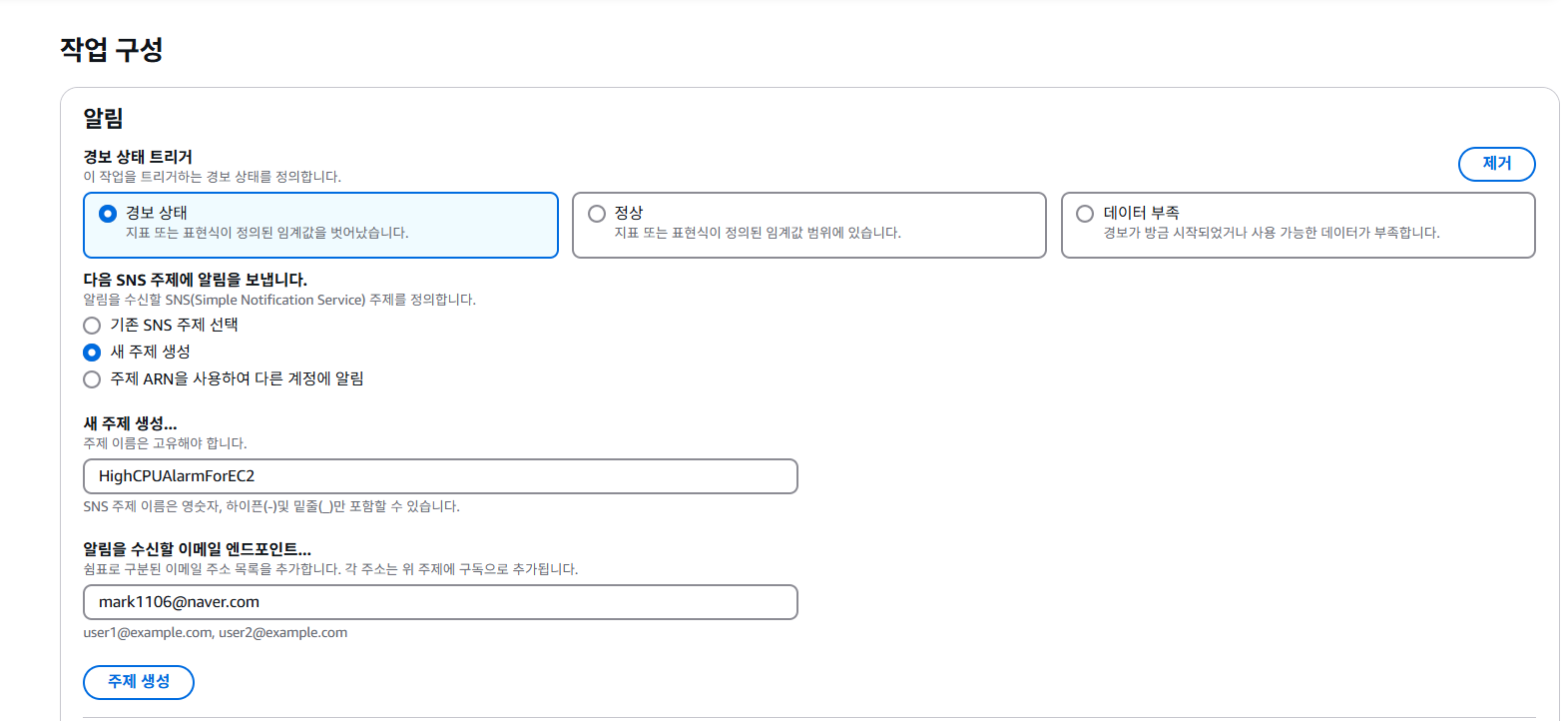
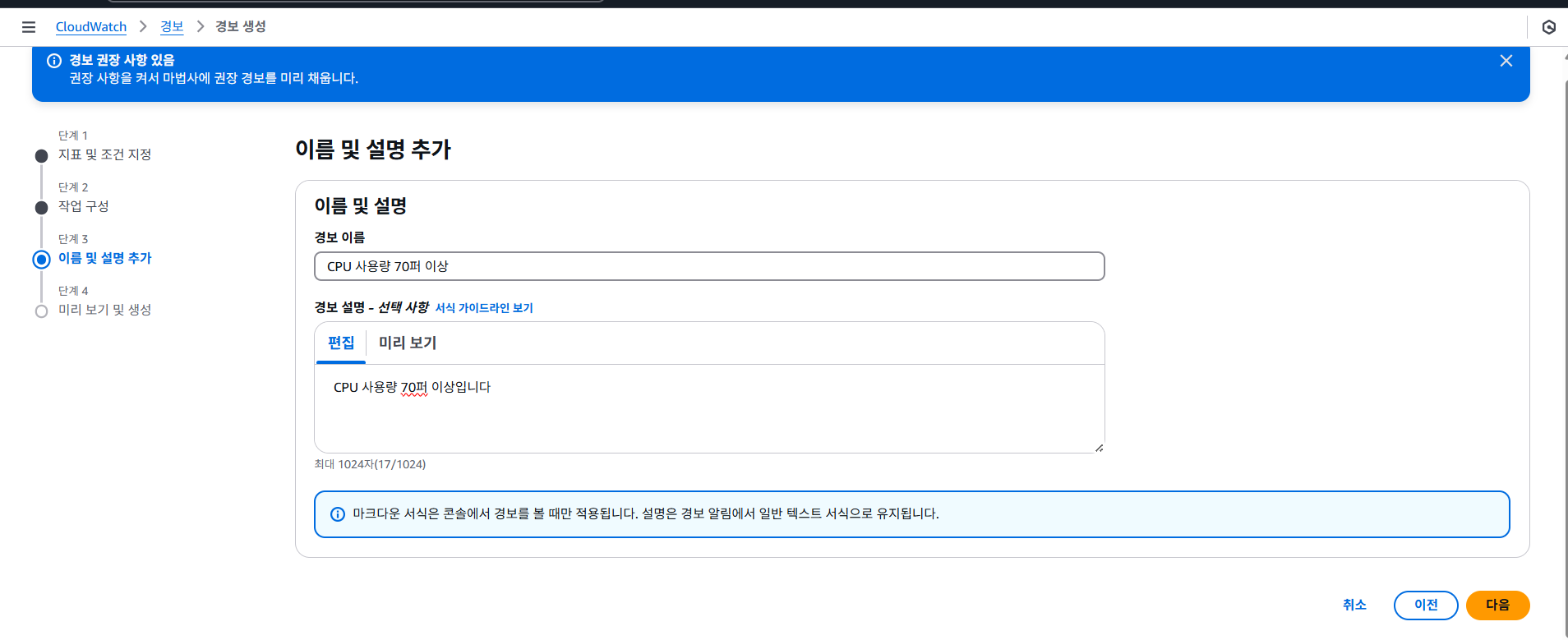
알림 보낼 이메일을 입력하고 경보에 대한 이름 및 설명을 추가한다.
CPU 부하 테스트 & 알림 확인
위와 같이 CPU 70% 이상 시 설정한 경보가 메일로 오도록 환경을 구성하였고 정상적으로 작동 가능한지 테스트를 진행해보았다.
1. 부하 테스트 환경
//부하 도구 설치
sudo yum -y install stress
// cpu 개수 확인
grep -c processor /proc/cpuinfo
// cpu 1개에 부하
stress -c 1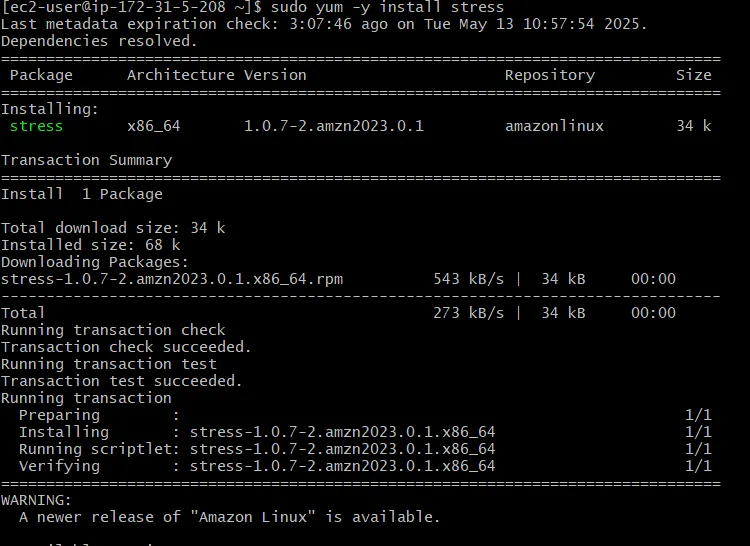
배포 환경에서 다음과 같은 명령어로 부하 도구를 설치한 후 stress 명령어로 cpu에 부하를 준다.
2. CloudWatch로 CPU Utilization 확인
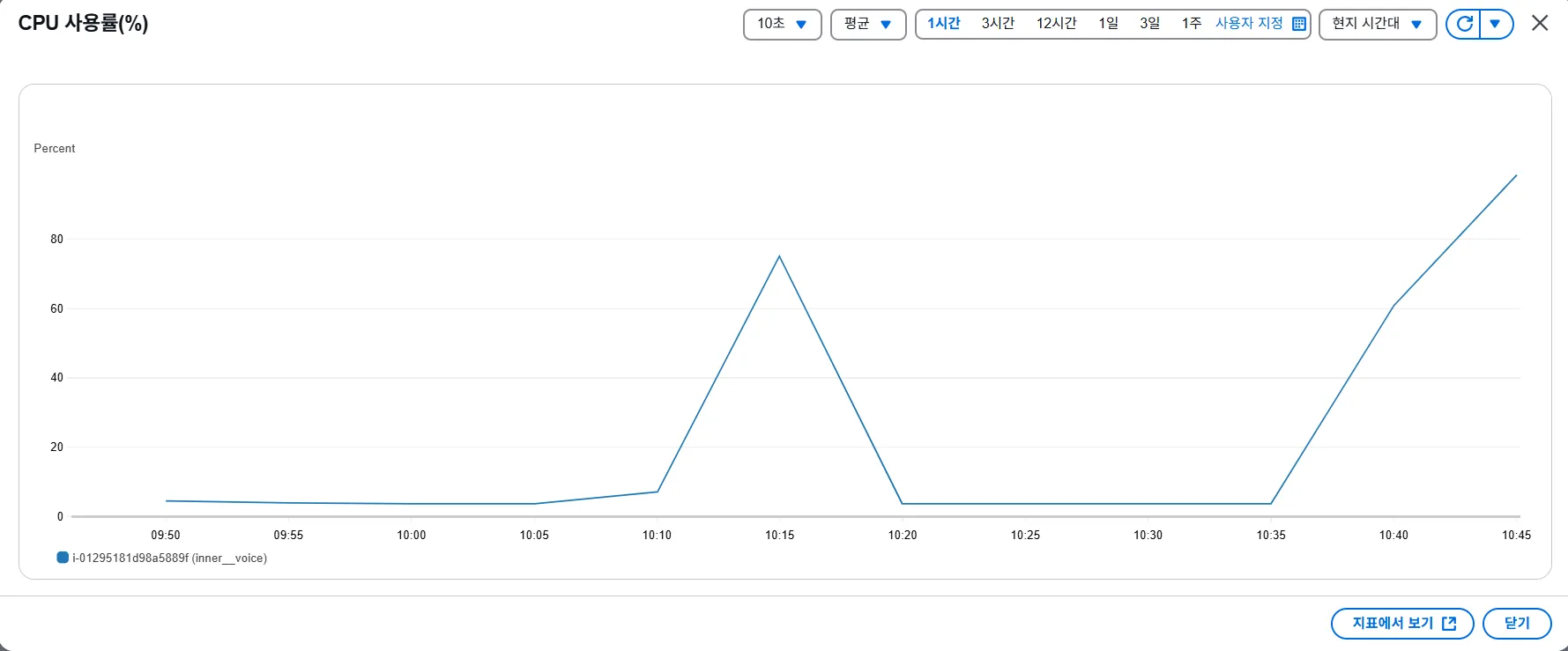
CloudWatch로 CPU 사용량을 확인해보면 부하를 준 시점에 CPU 사용률이 100%까지 도달하는 것을 볼 수 있다.
3. CPU 사용률 70% 초과 시 경보 & 알림 오는지 확인
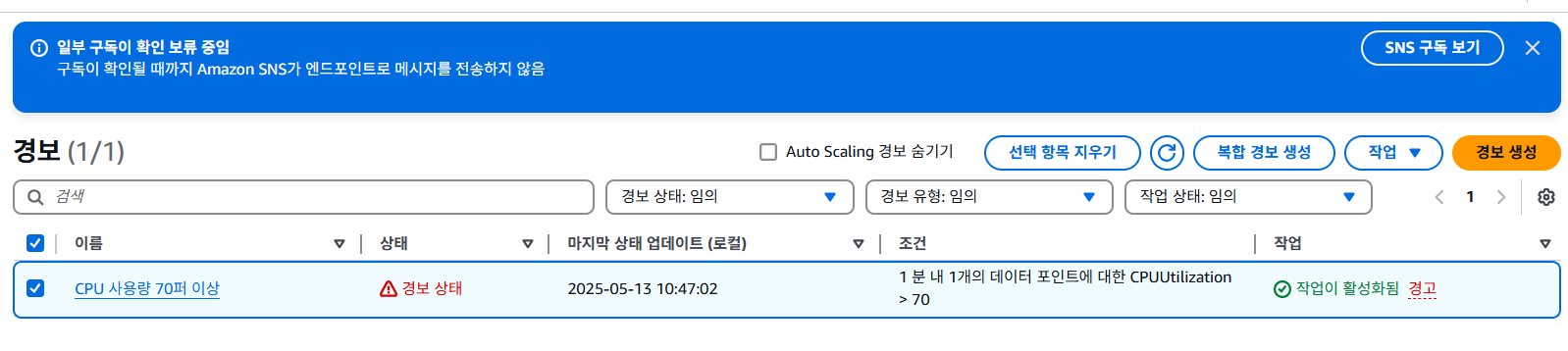
위에서 설정해둔 경보로 CPU 사용량 70%가 5분 이상 지속되면 상태가 변경된다.
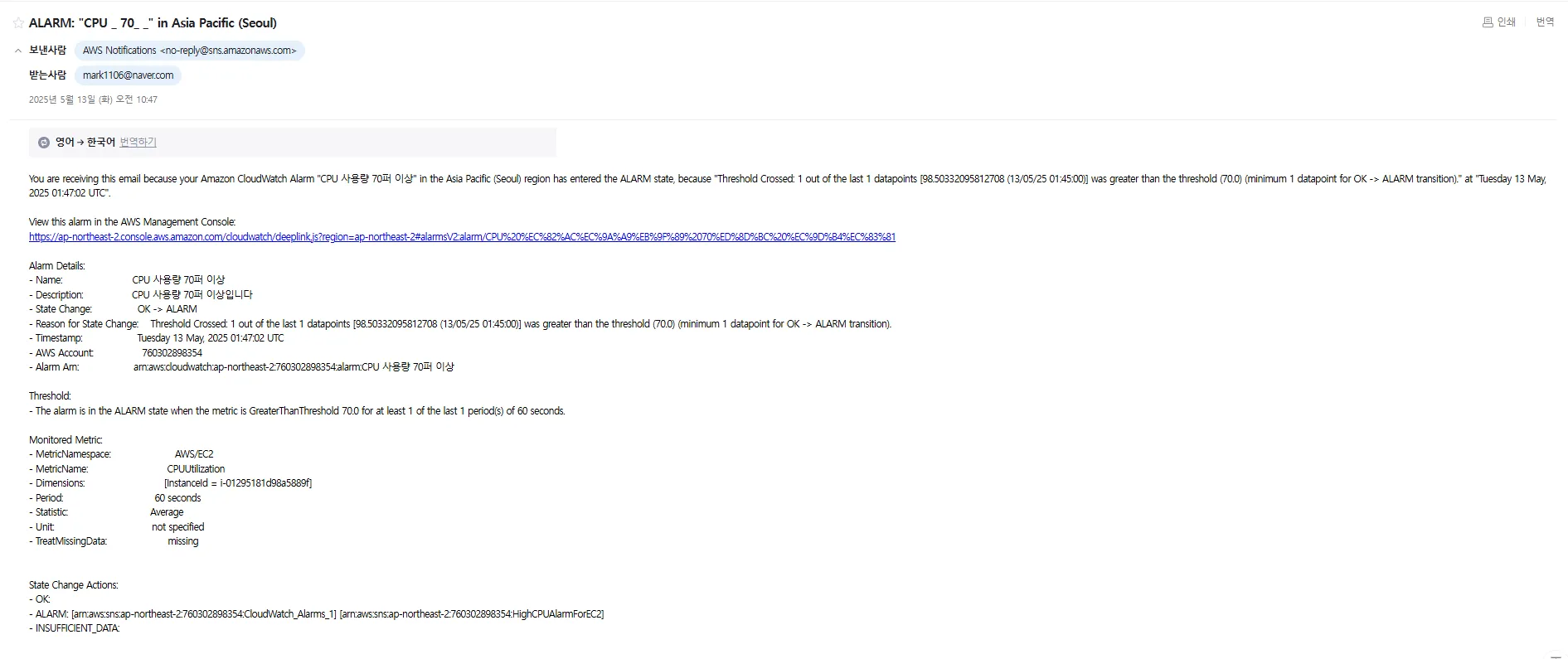
또한 설정했던 이메일에 설정해뒀던 경보 이름, 경보 발생 시간 등의 정보들이 제대로 오는 것을 확인할 수 있다.
3. 성과
실제 홍보 부스 운영 당일, 약 200명의 사용자가 앱을 동시에 다운로드 및 사용하면서 CPU 사용량 알림이 발생하였다. 해당 장애에 신속히 대응하기 위해 서버의 스케일업(scale-up)을 진행하였고, 임시 조치로 CPU와 메모리 자원을 물리적으로 확장하였다. scale-out을 하지 않은 이유는 실시간 통신 기능이 메시지 브로커 없이 단일 Socket 서버에 구축되어 있어 메시지 동기화에 문제가 발생할 수 있어 해결 할 수 있는 방안중 scale out을 선택했다.
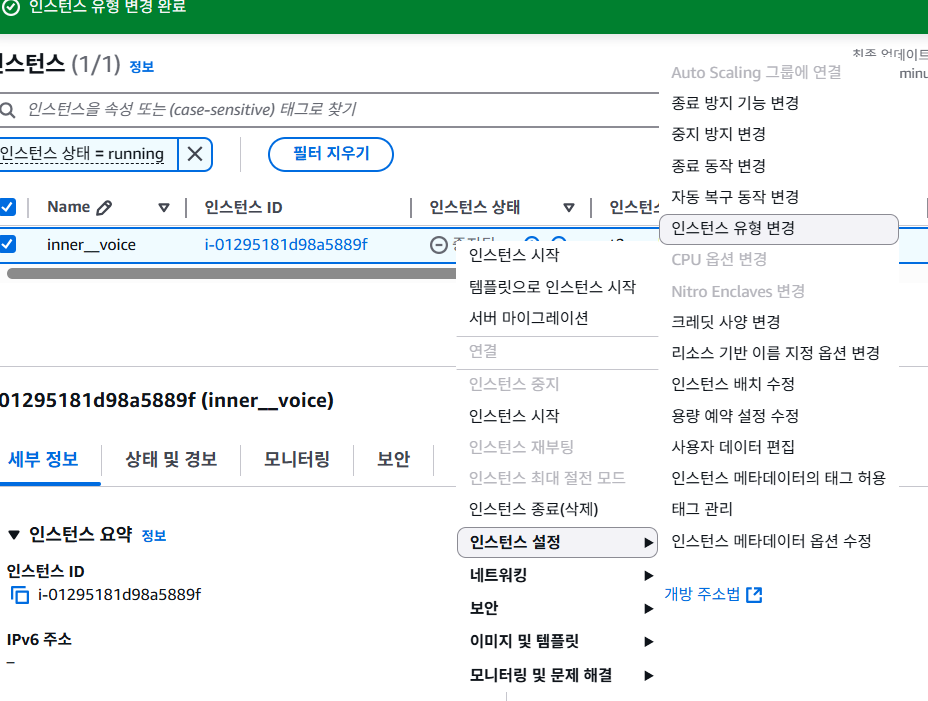
이 과정을 통해 실 서비스에서 모니터링의 필요성과 장애 발생 시 대응 과정에 대해 알게 되었고, 지표 기반의 실시간 알림 시스템과 자원 확장 전략의 중요성을 깨닫게 되었다.